A Linked Open Data project exploring the Byzantine Emperor Justinian and his cultural legacy across law, art, and history
EXPLORE THE PROJECTPROJECT
This ontology-based project was developed for the Information Science and Cultural Heritage course at the University of Bologna, taught by Professor Francesca Tomasi and Professor Marilena Daquino.
It focuses on the Byzantine Emperor Justinian I, collecting, analyzing, and semantically interlinking a curated set of cultural heritage items —including mosaics, buildings, historical documents, artifacts, audiovisual resources, and digital media—related to his reign and legacy.
Through Linked Open Data methodologies, the project constructs a dynamic knowledge graph, in which entities, drawn from diverse sources, are interconnected across disciplines and institutions. This not only enriches academic research but also ensures that Justinian’s multifaceted heritage — from the Corpus Iuris Civilis to the Hagia Sophia, from artistic representations to modern cultural reinterpretations — is preserved, accessible, and constantly recontextualized.
LOD are the foundation of the Semantic Web, an evolution of the traditional web that aims to make data understandable to machines as well. The goal is to transform the web into a network of semantically interconnected data.
To achieve this, the metadata provided by the institutions holding the selected items were transformed into semantic triples composed of a subject, a predicate, and an object. This is a key step in our project, and it is where RDF becomes essential. RDF is one of the fundamental technologies of the Semantic Web, used to structure and link data on the web. In addition to RDF, other technologies such as TEI/XML were used in the text analysis section.
STUDY OF THE DOMAIN
IDEA
"Cesare fui e son Iustiniano,
che, per voler del primo amor ch'i' sento,
d'entro le leggi trassi il troppo e 'l vano.
[...]
Tosto che con la Chiesa mossi i piedi,
a Dio per grazia piacque di spirarmi
l’alto lavoro, e tutto ‘n lui mi diedi;
e al mio Belisar commendai l’armi,
cui la destra del ciel fu sì congiunta,
che segno fu ch’i’ dovessi posarmi."
"Caesar I was, and am Justinian,
Who, by the will of primal Love I feel,
Took from the laws the useless and redundant.
[...]
As soon as with the Church I moved my feet,
God in his grace it pleased with this high task
To inspire me, and I gave me wholly to it,
And to my Belisarius I commended
The arms, to which was heaven's right hand so joined
It was a signal that I should repose."
The project stems from a collective reflection on the role of figures and monuments that serve as a junction between different cultural traditions.
Justinian I was chosen because, more than many other late antique rulers, he embodies
the tension and encounter between East and West: from the legal reforms of the
The popularity and resonance of Justinian’s image did not end with his lifetime. From Dante’s celebrated invocation in Paradiso to modern historiography, cinema, music and games, Justinian’s figure has been continuously reinterpreted. Contemporary media continue to reframe his achievements and controversies, showing how a sixth-century emperor still informs debates about law, empire, faith, and the interchange between East and West.
ITEMS
We conducted targeted research to identify ten key items directly connected to Justinian’s reign and later reception. The selection spans media and periods: mosaics and architecture, numismatics, manuscripts and legal codices, visual art, film and music, and contemporary games.
Sources combine institutional catalogues and museum collections (Catalogo Beni Culturali, Louvre, British Museum), digital archives and platforms (Internet Archive, YouTube, IMDb, BoardGameGeek), producing a compact dataset ready for semantic conversion and LOD analysis.
Mosaic from the Basilica di San Vitale in Ravenna
Basilica di San Vitale in Ravenna, a 6th-century Byzantine church, renowned for its mosaics including the iconic portrait of Emperor Justinian, exemplifying the union of political power and sacred art.
See moreDiptych Barberini
6th century ivory diptych depicting the triumphant Emperor Justinian on horseback.
See moreProcopius: History of the Wars
Loeb Classical Library edition (Greek text & English translation by H. B. Dewing). The book corresponds to Volume I, which contains Books I-II (The Persian War). This volume is also significant because it introduces for the first time the figure of Justinian I.
See moreCodex Florentinus (part of Corpus Iuris Civilis)
Manuscript dating back to the 6th century which reports almost entirely the most relevant part of the Digest, that is, a part of the Corpus Iuris Civilis, the collection of normative and jurisprudential material of Roman law commissioned by the emperor Justinian.
See moreCoin
Gold Coin representing the bust of Justinian I. The obverse features a bust of Justinian, wearing a
helmet and cuirass, facing forward, holding a spear and shield.
The reverse features an angel facing forward, holding a long cross and a cross on a globe
(globus cruciger).
Teodora, imperatrice di Bisanzio
This movie, also known as "Theodora, Slave Empress," tells the story of Teodora, a former courtesan who marries Emperor Justinian I and becomes the Empress of Byzantium. The film depicts her journey from her humble origins to the throne, where she displays great political acumen to save her husband's rule and deeply reform the state.
See moreHagia Sophia
Historic architectural marvel in Istanbul, originally built as a Christian church and completed in 537 AD under the Byzantine Emperor Justinian I.
See moreJustinian Epic Symphony
A symphony that recounts the fundamental events that occurred under the empire of Justinian I.
See moreCivilization (Videogame)
Videogame that offers a modern retelling of Justinian's reign, letting players rebuild the Byzantine Empire through lawmaking, diplomacy and large-scale military campaigns.
See moreJustinian: Intrigue at the Emperor's Court (Board Game)
Board game in which players bribe influential courtiers to gain the emperor’s favor. Bribes come in four colors, but only three are scored during the game. At the end of each turn, one color is scored, and players earn points based on their followers’ influence at court.
See moreKNOWLEDGE ORGANIZATION
Metadata Analysis
The first activity carried out by the team was the identification of the metadata standard adopted by the providers of the selected items, with the goal of ensuring interoperability. In cases where the institution had not explicitly stated the standard in use, the team decided to apply either the standard commonly adopted by similar institutions or the one deemed most suitable and relevant to the nature of the object, according to semantic accuracy and the context of usage of the formal grammar chosen.
| Item | Object Type | Provider | Provided Metadata | Converted Metadata |
|---|---|---|---|---|
| San Vitale Mosaic | Mosaic - Photographic Heritage | Catalogo Generale Beni Culturali | Arco | ArCo |
| Diptych Barberini | Artwork | Musée du Louvre | / | CIDOC-CRM |
| Procopius: History of the Wars | Translated Edition - Digital Facsimile | Internet Archive | MARCXML | DCTERMS |
| Codex Florentinus | Manuscript Codex - Digital Facsimile | Biblioteca Medicea Laurenziana | TEI/XML | DCTERMS |
| Coin with Justinian I | Coin | British Museum | MCEMS | NMO/DCTERMS |
| Teodora, imperatrice di Bisanzio | Movie | IMDb | / | Schema.org |
| Hagia Sophia | Historical Building - Architectural Record | Archnet | / | SCHEMA/DCTERMS |
| Justinian Epic Symphony (music) | Video | YouTube | / | Schema.org |
| Civilization (game) | Videogame | Civilization Fandom Wiki | / | SCHEMA/DCTERMS |
| Justinian: Intrigue at the Emperor's Court (game) | Game | Board Game | BoardGameGeek | SCHEMA/DCTERMS |
Theoretical Model
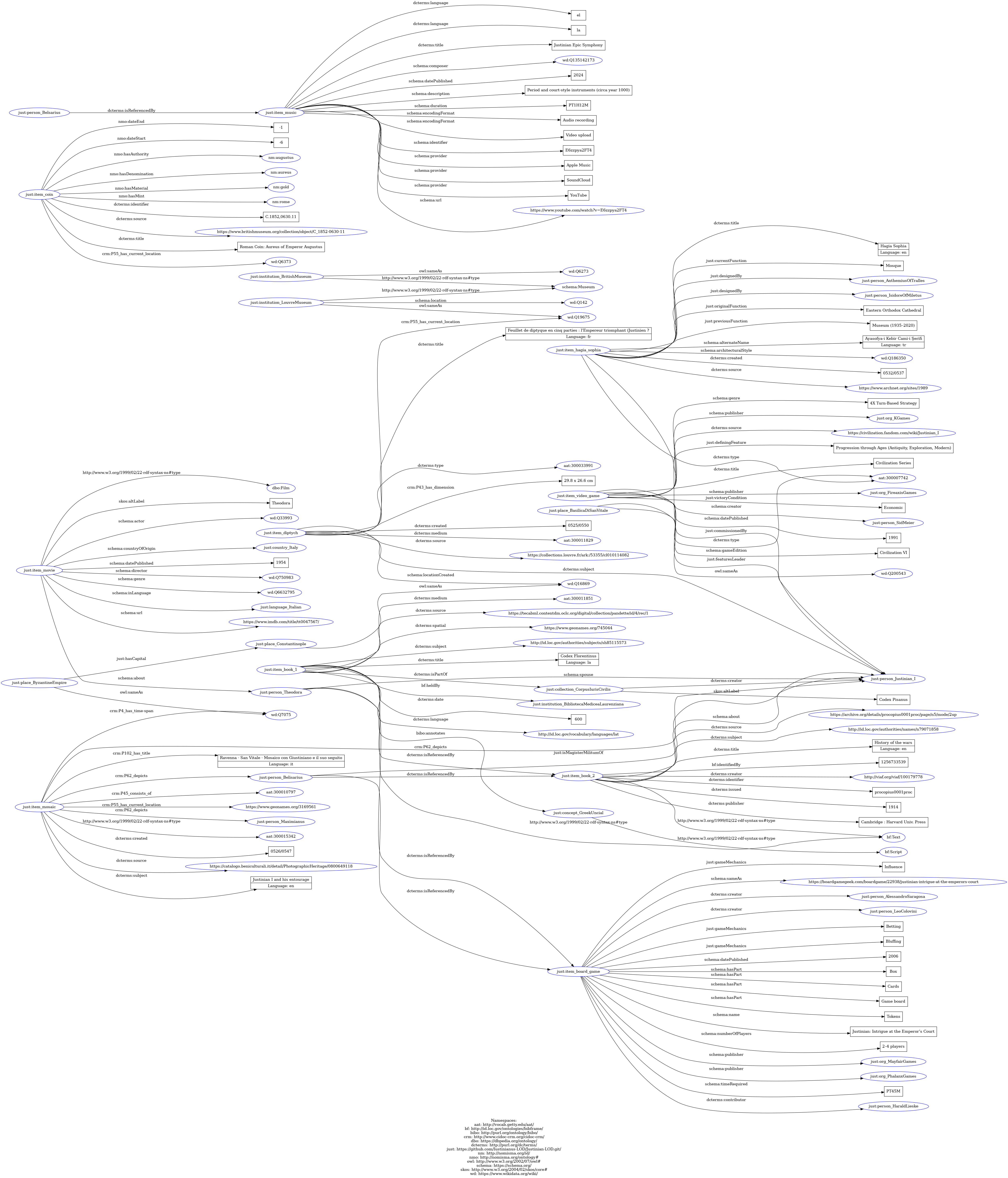
The Theoretical Model was developed by analysing the natural language descriptions of each cultural heritage item, as provided by the holding institutions. The goal was to capture the core knowledge about Justinian’s legacy in a structured yet human readable form. All statements were expressed as subject–>predicate–>object triples, following the pattern of Linked Open Data. This made it possible to explicitly show not only how each item relates to the central theme, being the multifaceted heritage of Emperor Justinian I, but also the network of connections among the items themselves.
Because not every institution supplied metadata according to a formal standard, we carefully aligned each predicate to the most appropriate vocabulary. Where necessary, predicates were adapted to maintain readability and to ensure consistency with authority files. Additional entities—such as historical figures (Theodora, Belisarius), places (Constantinople, Ravenna), and concepts (Corpus Iuris Civilis, Byzantine architecture) were introduced to enrich the dataset and to reveal further links across the items.
In the visualisation, different colours and shapes serve to distinguish the types of information, and to make it easier to navigate the map. Items are represented with distinct shapes and colors, while entities are shown in rectangular white and green boxes. Entities with a literal and/or numeric nature are shown with oval shaped green boxes. A legend in the diagram explains the visual encoding in detail.

Theoretical model (click on image to enlarge)
Conceptual Model
The Conceptual Model formalises the domain knowledge by defining the
classes, properties, and relationships that structure the dataset. Starting from
the theoretical model, each natural language triple was elevated to an abstract level and assigned a
suitable class or property from established ontologies. A custom base URI was
created to uniquely identify the resources of the project:
https://github.com/Iustinianus-LOD/Justinian-LOD/.
The selection of ontologies was driven by the nature of each item. For the Codex Florentinus and other bibliographic resources, the team adopted BIBFRAME, the standard for describing library materials. Museum objects—such as the Diptych Barberini, the San Vitale Mosaic, and the gold solidus—were modelled using CIDOC‑CRM, which offers the necessary granularity for cultural heritage artefacts. Schema.org and FOAF were employed for people, places, and organisations, ensuring interoperability with general purpose web applications. Nomisma.org ontologies provided the required specificity for the numismatic item (coin)
All classes and properties were selected on a case by case basis to guarantee semantic precision while preserving coherence across heterogeneous data sources. The resulting model thus reflects a careful balance between the richness of the original descriptions and the formal requirements of the Semantic Web.

Conceptual model (click on image to enlarge)
The full list of namespace prefixes used in our ontology includes:
- @prefix just: <https://iustinianus-lod.github.io/Justinian-LOD//>
- @prefix aat: <http://vocab.getty.edu/aat/>
- @prefix bf: <http://id.loc.gov/ontologies/bibframe/>
- @prefix bibo: <http://purl.org/ontology/bibo/>
- @prefix crm: <http://www.cidoc-crm.org/cidoc-crm/>
- @prefix dbo: <http://dbpedia.org/ontology/>
- @prefix dcterms: <http://purl.org/dc/terms/>
- @prefix nm: <http://nomisma.org/id/>
- @prefix nmo: <http://nomisma.org/ontology#>
- @prefix owl: <http://www.w3.org/2002/07/owl#>
- @prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
- @prefix schema: <https://schema.org/>
- @prefix skos: <http://www.w3.org/2004/02/skos/core#>
- @prefix wd: <https://www.wikidata.org/wiki/>
KNOWLEDGE REPRESENTATION
CSV FILES
Below is a collection of .csv files (one table per item) with the full natural-language description of our selected cultural heritage items.
The predicates were aligned to each source whenever possible; when not available, the mapping was completed by the team to balance precision and consistency for a later formal mapping.
Diptych Barberini
| Subject | Predicate | Object |
|---|---|---|
| Diptych Barberini | taken from | https://collections.louvre.fr/ark:/53355/cl010114082 |
| Diptych Barberini | has title | Feuillet de diptyque en cinq parties : l'Empereur triomphant (Justinien ?) |
| Diptych Barberini | has material | Ivory |
| Diptych Barberini | created in | 525 - 550 A.D. |
| Diptych Barberini | has type | Diptych |
| Diptych Barberini | landed by | Musée du Louvre, Département des Antiquités grecques, étrusques et romaines |
| Diptych Barberini | has height | 34,2 cm |
| Diptych Barberini | has subject | Justinian I |
| Diptych Barberini | originating from | Constantinople |
San Vitale Mosaic
| Subject | Predicate | Object |
|---|---|---|
| San Vitale Mosaic | taken from | https://catalogo.beniculturali.it/detail/PhotographicHeritage/0800649118 |
| San Vitale Mosaic | has title | Ravenna - San Vitale - Mosaico con Giustiniano e il suo seguito |
| San Vitale Mosaic | created in | 6th century |
| San Vitale Mosaic | has time period | Byzantine Empire |
| San Vitale Mosaic | has type | Mosaic |
| San Vitale Mosaic | has material | glass paste |
| San Vitale Mosaic | has subject | Justinian I and his entourage |
| San Vitale Mosaic | portrays | Justinian I |
| San Vitale Mosaic | portrays | Maximianus of Ravenna |
| San Vitale Mosaic | portrays | Belisarius |
| San Vitale Mosaic | located in | Basilica of San Vitale, Ravenna |
Codex Florentinus
| Subject | Predicate | Object |
|---|---|---|
| Codex Florentinus | Taken from | https://tecabml.contentdm.oclc.org/digital/collection/pandette/id/4/rec/1 |
| Codex Florentinus | is part of | Corpus Iuris Civilis |
| Codex Florentinus | held by | Biblioteca Medicea Laurenziana, Florence |
| Codex Florentinus | has type | Manuscript (Pandects) |
| Codex Florentinus | has language | Latin |
| Codex Florentinus | has date | 6th century CE |
| Codex Florentinus | has origin | Constantinople |
| Codex Florentinus | has material | Parchment |
| Codex Florentinus | has script | Greek uncial |
| Codex Florentinus | describes | Roman law |
Coin
| Subject | Predicate | Object |
|---|---|---|
| Coin | taken from | https://www.britishmuseum.org/collection/object/C_1852-0630-11 |
| Coin | has title | Gold solidus of Justinian I |
| Coin | has material | gold |
| Coin | has type | coin |
| Coin | has authority | Justinian |
| Coin | minted in | Constantinople |
| Coin | has date | 527-565 |
| Coin | has die-axis | 6 o'clock |
| Coin | has diameter | 21 millimetres (max) |
| Coin | has weight | 4.354 grammes |
| Coin | is located in | The British Museum |
| Coin | has museum ID | 1867,0101.1015 |
Theodora, slave empress
| Subject | Predicate | Object |
|---|---|---|
| Theodora, slave empress | taken from | https://www.imdb.com/title/tt0047567/ |
| Theodora, slave empress | has original title | Teodora, l'imperatrice di Bisanzio |
| Theodora, slave empress | has release year | 1954 |
| Theodora, slave empress | has type | Film |
| Theodora, slave empress | directed by | Riccardo Freda |
| Theodora, slave empress | produced in | Italy |
| Theodora, slave empress | has language | Italian |
| Theodora, slave empress | depicts | Theodora |
| Theodora, slave empress | has genre | Historical drama |
| Theodora, slave empress | has actor | Gianna Maria Canale |
Hagia Sophia
| Subject | Predicate | Object |
|---|---|---|
| Hagia Sophia | taken from | https://www.archnet.org/sites/1989 |
| Hagia Sophia | has type | Religious Architecture |
| Hagia Sophia | also known as | Ayasofya-i Kebir Cami-i Şerifi |
| Hagia Sophia | has construction period | 532–537 CE |
| Hagia Sophia | commissioned by | Justinian I |
| Hagia Sophia | designed by | Anthemius of Tralles; Isidore of Miletus |
| Hagia Sophia | has architectural style | Byzantine |
| Hagia Sophia | original function | Eastern Orthodox Cathedral |
| Hagia Sophia | previous function | Museum (1935–2020) |
| Hagia Sophia | current function | Mosque |
History of the wars
| Subject | Predicate | Object |
|---|---|---|
| History of the wars | taken from | https://archive.org/details/procopius0001proc/page/n5/mode/2up |
| History of the wars | has type | book |
| History of the wars | has author | Procopius |
| History of the wars | has title | History of the wars |
| History of the wars | has publisher | Cambridge : Harvard Univ. Press |
| History of the wars | has publication date | 1914 |
| History of the wars | has translator | H.B. Bronson |
| History of the wars | has identifier | procopius0001proc |
| History of the wars | has OCLC identifier | 1256733539 |
| History of the wars | has subject | Justinian I |
| History of the wars | has subject | Byzantine Empire |
| History of the wars | has subject | The Persian war |
| History of the wars | has language | English |
| History of the wars | has language | Greek |
Justinian Epic Symphony
| Subject | Predicate | Object |
|---|---|---|
| Justinian Epic Symphony | Taken from | https://www.youtube.com/watch?v=E6zzpya2FT4 |
| Justinian Epic Symphony | has title | Justinian Epic Symphony |
| Justinian Epic Symphony | has subject | Justinian I |
| Justinian Epic Symphony | has composer | Farya Faraji |
| Justinian Epic Symphony | has release date | 2023 |
| Justinian Epic Symphony | has format | Audio recording; Video upload |
| Justinian Epic Symphony | has duration | Approximately 1 hour 12 minutes |
| Justinian Epic Symphony | has language | Latin |
| Justinian Epic Symphony | has language | Greek |
| Justinian Epic Symphony | has instrumentation note | Period and court-style instruments (circa year 1000) |
| Justinian Epic Symphony | distributed on | YouTube; Apple Music; SoundCloud |
| Justinian Epic Symphony | has YouTube ID | E6zzpya2FT4 |
Civilization
| Subject | Predicate | Object |
|---|---|---|
| Civilization | taken from | https://civilization.fandom.com/wiki/Justinian_I |
| Civilization | has genre | 4X Turn-Based Strategy |
| Civilization | first released in | 1991 |
| Civilization | created by | Sid Meier |
| Civilization | developed by | Firaxis Games |
| Civilization | published by | 2K Games |
| Civilization | latest main installment | Civilization VII |
| Civilization | has defining feature | Progression through Ages (Antiquity, Exploration, Modern) |
| Civilization | has victory condition | Economic |
| Civilization | has features leader | Justinian I |
Justinian: Intrigue at the Emperor’s Court
| Subject | Predicate | Object |
|---|---|---|
| Justinian: Intrigue at the Emperor’s Court | taken from | https://boardgamegeek.com/boardgame/22938/justinian-intrigue-at-the-emperors-court |
| Justinian: Intrigue at the Emperor’s Court | has title | Justinian: Intrigue at the Emperor’s Court |
| Justinian: Intrigue at the Emperor's Court | has subject | Justinian I |
| Justinian: Intrigue at the Emperor’s Court | has designers | Leo Colovini; Alessandro Saragosa |
| Justinian: Intrigue at the Emperor’s Court | has publisher | Phalanx Games; Mayfair Games |
| Justinian: Intrigue at the Emperor’s Court | has year published | 2006 |
| Justinian: Intrigue at the Emperor’s Court | has artist | Harald Lieske |
| Justinian: Intrigue at the Emperor’s Court | has player count | 2–4 players |
| Justinian: Intrigue at the Emperor’s Court | has playing time | approximately 45 minutes |
| Justinian: Intrigue at the Emperor’s Court | has mechanics | Bluffing; Influence; Betting |
| Justinian: Intrigue at the Emperor’s Court | has components | Game board; Tokens; Cards; Box |
Additional CSV
| Subject | Predicate | Object |
|---|---|---|
| Belisarius | is part of | Justinian Epic Simphony |
| Belisarius | is part of | Justinian: Intrigue at the Emperor's court |
| Belisarius | is part of | History of the Wars |
| Belisarius | is magister militum of | Justinian I |
| Theodora | is wife of | Justinian I |
| Theodora | is part of | History of the Wars |
| Theodora | is part of | Justinian: Intrigue at the Emperor's court |
| Louvre Museum | has type | museum |
| British Museum | has type | museum |
| Louvre Museum | is located in | France |
| Codex Florentinus | also known as | Codex Pisanus |
| Hagia Sophia | has label | Religious Architecture |
| Basilica di San Vitale | has label | Religious Architecture |
| Corpus Iuris Civilis | has authority | Justinian I |
| Greek uncial | is a | writing script |
| Byzantine Empire | has capital | Constantinople |
RDF PRODUCTION
CSV Files in Formal Language
From these natural language CSV files, another set of CSV files is created using formal language. These files will be found under the folder “csv_files/Formal_language” within the project’s repository. The files will have the same structure as the natural language files, following the subject-predicate-object form, so that every statement could be traced back to its equivalent form in natural language and mapped into a semantic triple.
The formalization process consisted of two parallel operations:
- For the predicates, every relationship identified in the natural language description was associated with a property from a predefined ontology or vocabulary. Dublin Core (dcterms) was used for generic descriptive metadata such as title, date, language, and source. BIBFRAME was used for bibliographic resources, CIDOC-CRM for cultural heritage objects and events, Schema.org for media items and generic descriptions, and the Nomisma Ontology (nmo) for the coin.
- For the objects, every value was associated with a URI from an authority-controlled resource rather than being represented as a plain string. VIAF was used for people and authors, Wikidata for historical concepts and entities, GeoNames for geographical locations, and Getty AAT for object types and materials.
Entities that are central to the project but not held by any particular institution — such as
Justinian I, Theodora, Belisarius, the Byzantine Empire, and the Corpus Iuris Civilis — were
assigned custom URIs under the project's base namespace (just:).
Two additional CSV files were also created to describe relationships between entities that are not items themselves but are relevant to the dataset. These include relationships between historical figures and the items in which they appear, descriptions of the museums that hold the items, and the relationship between the Byzantine Empire and its capital Constantinople. owl:sameAs statements were also added to align the project's custom URIs with their equivalent Wikidata entries, ensuring interoperability with the broader Linked Open Data ecosystem.
Python Script for Transformation
The RDF dataset is produced programmatically by a Python script using the rdflib, csv and glob libraries. The script initializes an RDF graph, declares namespace prefixes, and processes every CSV file found in the csv_files/Formal_language folder. Files are parsed with csv.DictReader, which reads the header row automatically and yields subject–predicate–object rows.
For each row the script expands CURIEs to full URIs using the prefix map, accepts full
http/https URIs directly, and normalizes casing when needed. Objects
are handled according to their content:
- Values wrapped in angle brackets (
<>) are treated as URI references. - CURIEs are expanded using the prefix map.
- Language-tagged values (e.g.
@en,@la) become language-tagged literals. - Four-digit values within the historical year range are mapped to
xsd:gYear. - Other numeric values are mapped to
xsd:integer. - Remaining values are stored as plain string literals.
If a subject or predicate cannot be resolved to a known CURIE or URI, the row is skipped and reported on the console to make source correction easy. After processing all files the graph is serialized to Turtle as full_dataset.ttl, chosen for its readability and broad tooling support.
What the script does specifically:
- Initialises a graph and binds namespace prefixes.
- Reads all
.csvfiles incsv_files/Formal_languageusingDictReader. - Expands subjects/predicates from CURIEs or accepts full URIs; parses objects into URIs or typed literals.
- Adds triples to the graph and writes the resulting Turtle file (
full_dataset.ttl).
RDF Dataset
Our final output:
RDF Visualization
RDF Visualization (click to enlarge)
TEXT ANALYSIS
XML/TEI document
Our coding work focused on selected excerpts from Procopius's History of the Wars. Specifically, we coded the Introduction and Chapters XIII-XIV of Book I in Loeb's English translation as represented in the Internet Archive copy.
The excerpts were chosen because they explicitly situate the initial phase of Justinian's reign in the Persian (Mesopotamian) theater of operations and introduce key actors and events used in our LOD case study. Chapter XIII, in particular, introduces Justinian in the context of the war against the Persians and describes the appointment of Belisarius and the preparations for the battle. Chapter XIV continues the narrative of the campaign and contains further descriptions of troop deployments, commanders, and locations.
To validate the XML/TEI document, we used the XML/TEI plugin for VS Code.
Main sections of the XML/TEI document:
<teiHeader>
Contains all metadata relating to the work and its digital edition. It is divided into several subsections:
-
<fileDesc>— Describes the electronic resource, including the title of the digital edition, the author, the digital editor, and the publication and licensing information. It also provides a bibliographic description of the original source used for the encoding. -
<encodingDesc>— Explains the editorial principles and encoding choices. For example, pb/ has been used to preserve the page breaks of the original edition. -
<profileDesc>— Details non-bibliographic features of the text, such as language, text type and thematic classification.It also includes structured metadata such as lists of people and places relevant to the encoded text. In the body of the text, personal and place names are marked with @ref, which links each occurrence to the corresponding xml:id in the teiHeader. This structure makes it possible to connect the encoded entities to external authority identifiers, such as Wikidata.
Furthermore, keywords considered meaningful for the project are included to highlight the central themes of the encoded text.
<text>
Contains the actual text of the work.
-
<front>— Includes the preliminary parts, such as the title page and part of the preface. -
<body>— Contains the selected excerpts from the main body of the text. Proper names are enclosed in persName and place names in placeName.
From XML to HTML
We have produced a stylesheet with XSL extension, a file that contains the rules for identifying XML nodes in the source document (using XPath), specifying how to manipulate them, and saving them in a new HTML file.
In particular, XSLT processes the XML document by following its hierarchical tree structure, starting from the root (/tei:TEI) and recursively applying templates to all child elements. The XSL file defines templates that specify the rules for transforming specific XML elements into corresponding HTML elements.
The XSLT transformation process was structured to extract and reorganize the metadata from the TEI header of the XML document, converting them into dedicated and well-formatted HTML sections. All descriptive information has been extracted and presented: metadata from both the original 1865 edition and the current digital edition, as well as a specific section dedicated to displaying the list of cited people and places mentioned, linked to external resources such as Wikidata and GeoNames, along with the keywords highlighted in the text, all organized for clear and immediate consultation.
Regarding the processing of the actual text, specific templates were created to handle all structural elements (such as divisions into chapters and sections) and textual elements (e.g. paragraphs), preserving the original semantic attributes.
The adopted approach maintains a clear separation between content and presentation: the XSL stylesheet deals exclusively with structure and semantic transformation, while all visual formatting rules are delegated to embedded CSS, thus ensuring a well-structured and aesthetically coherent HTML output.
Once the XSL file was produced, both it and the XML file were uploaded to an online tool called Free Formatter to generate the corresponding HTML file, which was then converted into a browsable HTML page.
XML/TEI to RDF
In order to extend the Linked Open Data model of the project to include the encoded textual source, a Python script was developed to convert the XML/TEI document of the Procopius encoding into an RDF dataset.
The conversion process was designed to leverage the structured metadata already encoded in
the TEI document. Entities recorded in the <teiHeader> — such as
historical figures listed in the <listPerson> element and geographical
locations in the <listPlace> element — were extracted and assigned URIs
under the project's base namespace. Where the TEI encoding already contained references to
external authority resources such as Wikidata or VIAF,
these were reused directly as owl:sameAs statements in the resulting RDF
dataset, ensuring alignment with the broader Linked Open Data ecosystem.
Descriptive properties were represented using the same ontologies employed throughout the project: dcterms for bibliographic metadata and foaf for describing individuals. The resulting graph was then serialized in Turtle (.ttl) format, producing an RDF file that complements the main dataset and can be queried and browsed alongside it. Validation was performed using the W3C RDF Validator to confirm the syntactic correctness of the file before publication.
Team
Information Science and Cultural Heritage Students

Maria Concetta
De Matteis
Master's degree student of DHDK at the University of Bologna
Master of Archaeology

Rumana Mehboob
Master's degree student of DHDK at the University of Bologna
Bachelor of Humanities

Kourosh "Cyrus" Shahbazi
Master's degree student of DHDK at the University of Bologna
Bachelor of Teaching English as a Foreign Language